How Can Artificial Intelligence be Applied in Automation Testing of Web Apps?

There are several interesting web app automation scenarios that we can improve using Artificial Intelligence (AI): Increase test execution stability (self-healing automation) by letting AI to automatically locate web elements when the primary locators fail. This feature already appears in some cutting-edge automation tools like Mabl. Increase automation productivity by using Natural Language Processing (NLP) to automatically translate […]
How to Choose the Best Testing Tool for Automated Testing
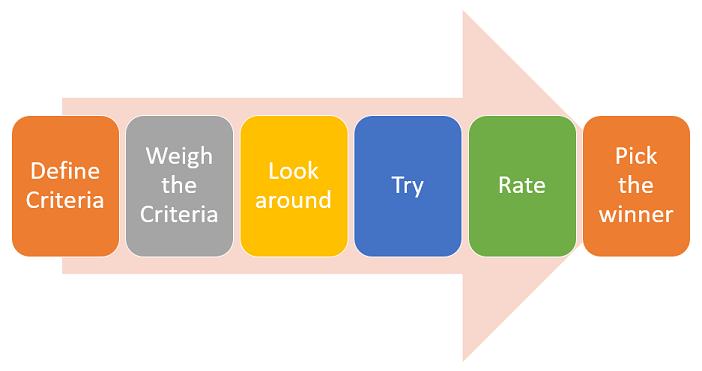
I’ve noticed that the process of choosing the best automation testing tool for a project is not always clear. So I’d like to shed some more light on it. The process (Choose the Best Testing Tool) should look like this. 1. Define a list of criteria Define a list of criteria that your ideal Test […]
Where is Software Testing Heading?
Just like other vibrant industries, software testing is changing every day. As a tester, what should you learn to stay on top of your game? Below are some trends you might want to take a look at in 2018. Sharpen the saw! Blockchain app testing: Unless you’ve been living under a rock for the past few […]
Demystifying 3 Common Misconceptions About Xpath In Web Automation

Problem Element identification lies at the core of automating web tests because without it, your test automation tool has no clue about how to locate and interact with the correct web elements on your application under test. As recommended by W3C, XPath is today’s solution of choice widely adopted by many web automation solutions including the famous Selenium framework. However, just […]