Passing strings between MQL and C++ DLL
MetaTrader is a popular platform used for forex trading, and other financial products trading (stock, commodity…) It provides to user the ability to add more features to the platform using its own language MQL. You can program your own indicator and your expert advisor to work with MetaTrader. The powerful of MQL is that it […]
Format a WD drive on MacOS
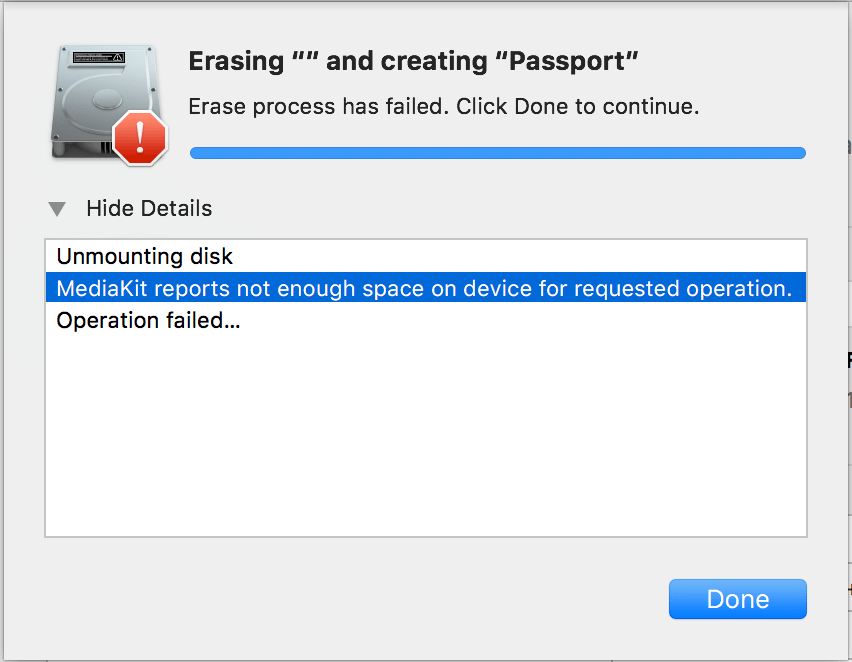
A friend of mine recommended WD drive My Passport (4TB) for me because I need one. The current one (SeaGate) is not stable, sometime it is not recognizable. I suspect it is due to the cable. Anyway I need more space for my massive data so I grabbed WD My Passport Ultra Metal Edition. NTFS […]
Hello World from Developer’s Notes

Welcome to Developer’s Notes. This site is reserved for notes that my friends and I learn and use daily basis. If you have some, you are more than welcome to join us. Someone may be benefit from your notes. A little bit about history of Developer’s Notes. Sometimes I don’t take note since I think […]